AI automation is not a dualistic experience. One of the dangers of the hype over-attributing capabilities of a system is, we lose sight of the fact that automation is a continuum as opposed to a discrete state. In addition to stoking irrational fears about automation, this kind of thinking also throws out of the window any exciting partial-automation possibilities (and products) that lie on the spectrum.
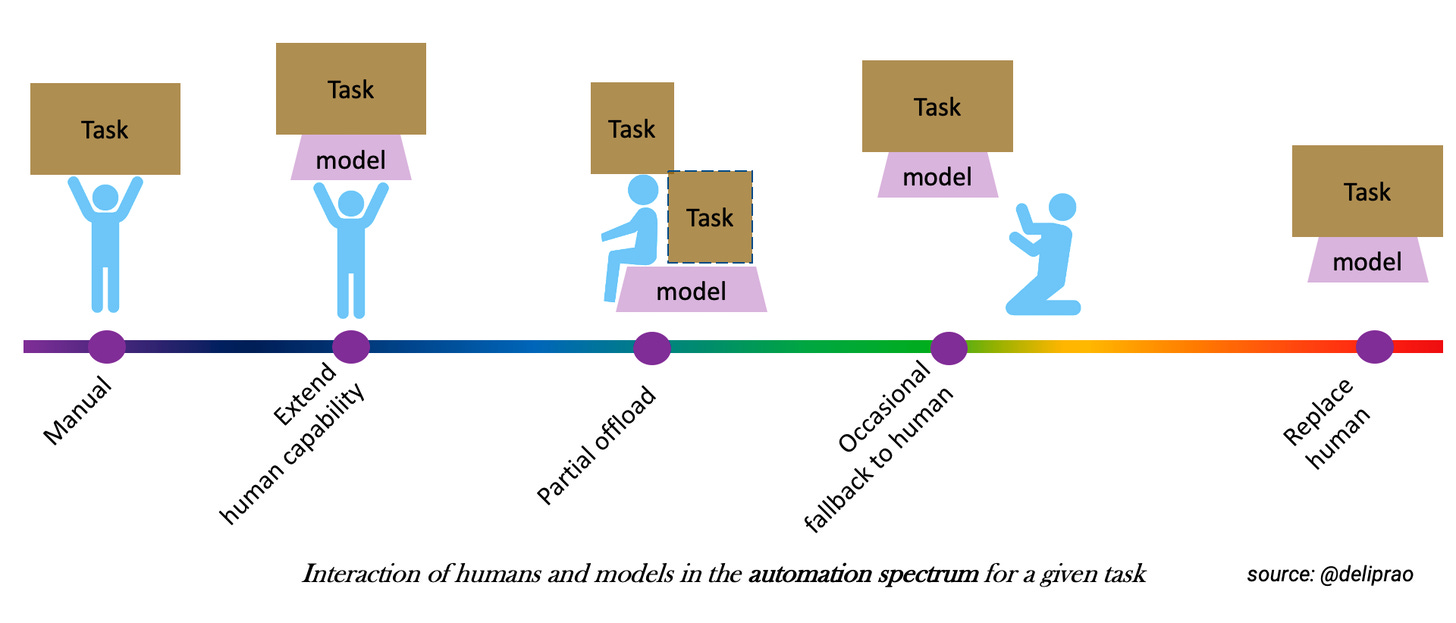
For convenience, we can break up the automation spectrum offered by the deployment of AI models for a task into five ordered levels:
- Manual: Human does all the job for the task.
- Extend: Model extends/augments the human capability for the task.
- Offload: Model partially offloads the complexity of the task (more on this later) by automatically solving some of it.
- Fallback: Model solves the task entirely most times, and occasionally, it cedes control to humans because of the complexity of the task or the human voluntarily takes over for whatever reason.
- Replace: The human becomes irrelevant in solving the task.
I am deriving this categorization from Sheridan and Verplanck’s 1978 study on undersea teleoperators but adapted for modern AI models. On the surface, this representation might appear similar to SEA levels of autonomous driving (those were influenced by the 1978 study as well). Still, the critical difference in this article is the inclusion of the task and the relation between the model, application, and the task. The SEA autonomous driving levels, on the other hand, are focused on a fixed task — driving on “publicly accessible roadways (including parking areas and private campuses that permit public access)”. We cannot talk about the automation capabilities of a model in isolation without the task and its application considered together.
The Interplay of Task and Application Complexity in AI Automation
Traditional software automation is focused on a specific task and any work related to it is built from scratch. AI model-based automation on the other hand is unique in the sense that you can have a model trained on one task — say face recognition — and used in multiple applications ranging from unlocking your phone to matching a suspect against a criminal database. Each of those applications has a different tolerance for false-positives/false-negatives (aka. “risk”). This train-once-use-everywhere pattern is becoming increasingly popular with large parameter models that are trained on massive datasets with expensive compute. This pattern is especially true with large model fine-tuning and also with recent zero-shot and few-shot models.
While this pattern is cheap and convenient, a lot of the problems in AI deployments result from transferring expectations on a model from its use in one scenario to another and being unable to quantify the domain-specific risk correctly. Sometimes, just retraining the model on the application-specific dataset may not be sufficient without making changes to the architecture of the model (“architecture engineering”) to handle dataset-specific nuances.
To illustrate the dependence of automation level on the task and application consider, for example, the task of machine translation of natural language texts. Google has one of the largest models for machine translation, so let’s consider that as our model of choice. The translation model, and certainly its API, appear general enough to give an unsuspecting user to try it on her favorite application. Now let’s consider a few application categories where machine translation can be applied — News, Poetry, Movie subtitles, Medical transcripts, and so on. Notice that for the same model and same task, depending on the application, the automation levels vary widely. So it never makes sense to assign “automation levels” to a model or to a task or an application, but the combination of the model and the application.
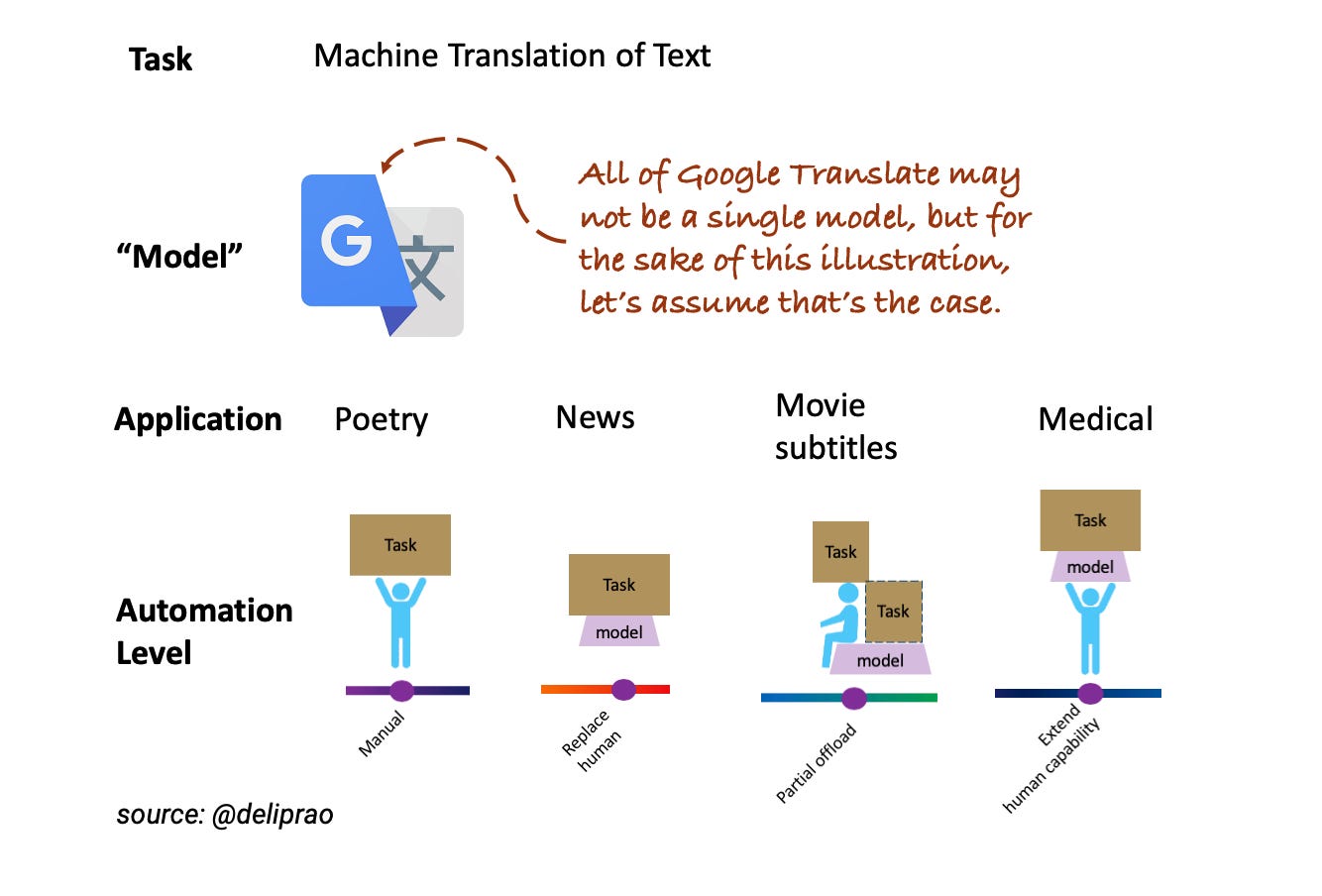
The automation level assignments in this figure are approximate and may not reflect Google’s current systems. This example is also overly simplified as performance on “news” may also not be homogenous. Translation qualities may be different across different news domains — e.g., financial news vs. political news — or across different languages. Yet this simplification is useful for illustration purposes.
Hype (and the subsequent user dissatisfaction) often happens when folks conflate, knowingly or unknowingly, the automation level offered in one application to another. For example, someone claiming all of humanity’s poetry will be accessible in English after their experience translating news articles to English.
To consider an example with GPT-3, the success of the AI Dungeon, a text adventure game, is an example of such a phenomenon. In the case of AI Dungeon, the outputs of the model could be interpreted creatively in any way you like (i.e., there are very few “wrong” answers by the model, if any). The error margin is effectively infinity offering zero risk in directly deploying the model modulo some post hoc filtering for toxic/obscene language and avoiding sensitive topics. Based on those outcomes, it wouldn’t make sense to deploy the model unattended as it stands today, say, for business applications. And in some cases, like healthcare, it may make sense not to deploy the model at all.
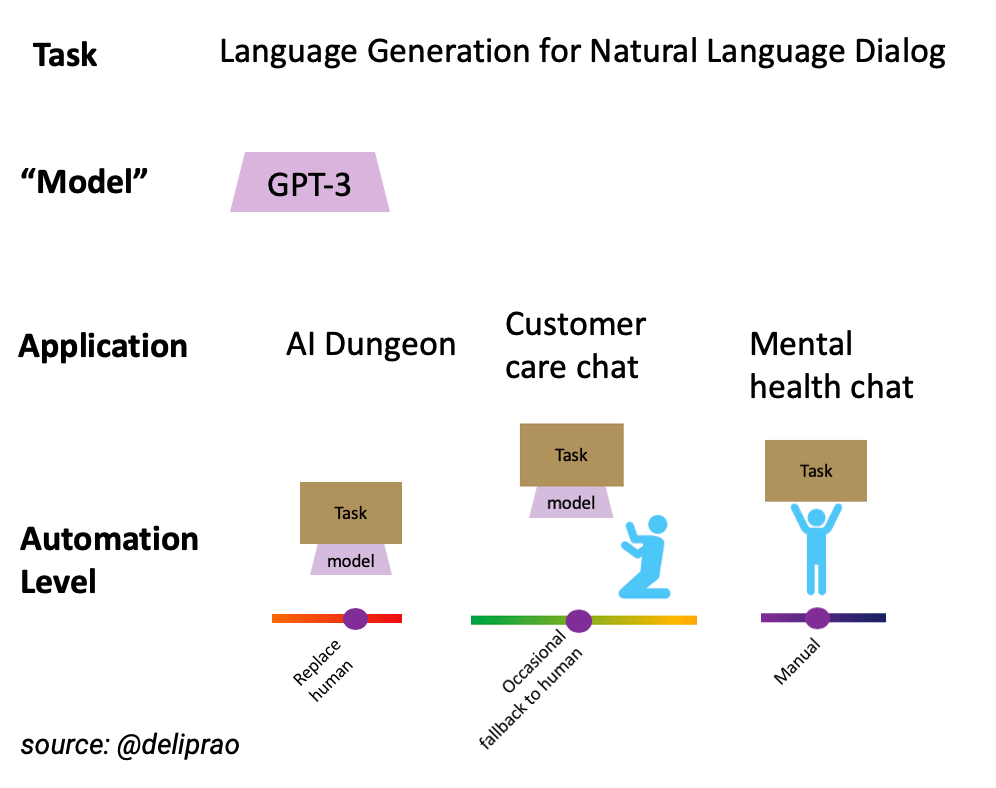
Aside 1: So far, when we consider situations where models “fallback” to humans we haven’t considered the thorny problem of knowing when to fallback. Today’s Deep Learning models, including GPT-3, are incredibly bad at telling when they are unsure about a prediction, so situations which require reliable fallback to humans cannot take advantage of such models.
Aside 2: Modeling improvements can push a model’s generalization capability across a wide range of applications, but their deployability will still widely vary. In fact, in risk intolerant applications with very little margin for acceptable error (consider the use of facial recognition for policing), we may choose to never deploy a model. Whereas in other applications, say use of facial recognition to organize photos, the margin of acceptable error may be wide enough that one might just give a shrug about the model fails, and hope for a better model update in the future.
Edwards, Perrone, and Doyle (2020) explore the idea of assigning automation levels to “language generation”. This is poorly defined as language generation, unlike self-driving, is not a task, but a means to accomplish one of the many tasks in NLP like dialogue, summarization, QA, and so on. For that reason, it does not make sense to assign an automation level for GPT-3’s language generation capabilities without also considering the task in question.
Capability Surfaces, Task Entropy, and Automatability
Another way to view the performance of a model on a task is to consider it’s Capability Surface. To develop this concept, first let’s consider an arbitrary, but fixed, ordering of the applications (domains) where the model trained on a task is applied. Now, for each application, let’s plot the automation capability levels of the model across different domains. Now, consider an imaginary “surface” that connects through these points. Let’s call this the capability surface.
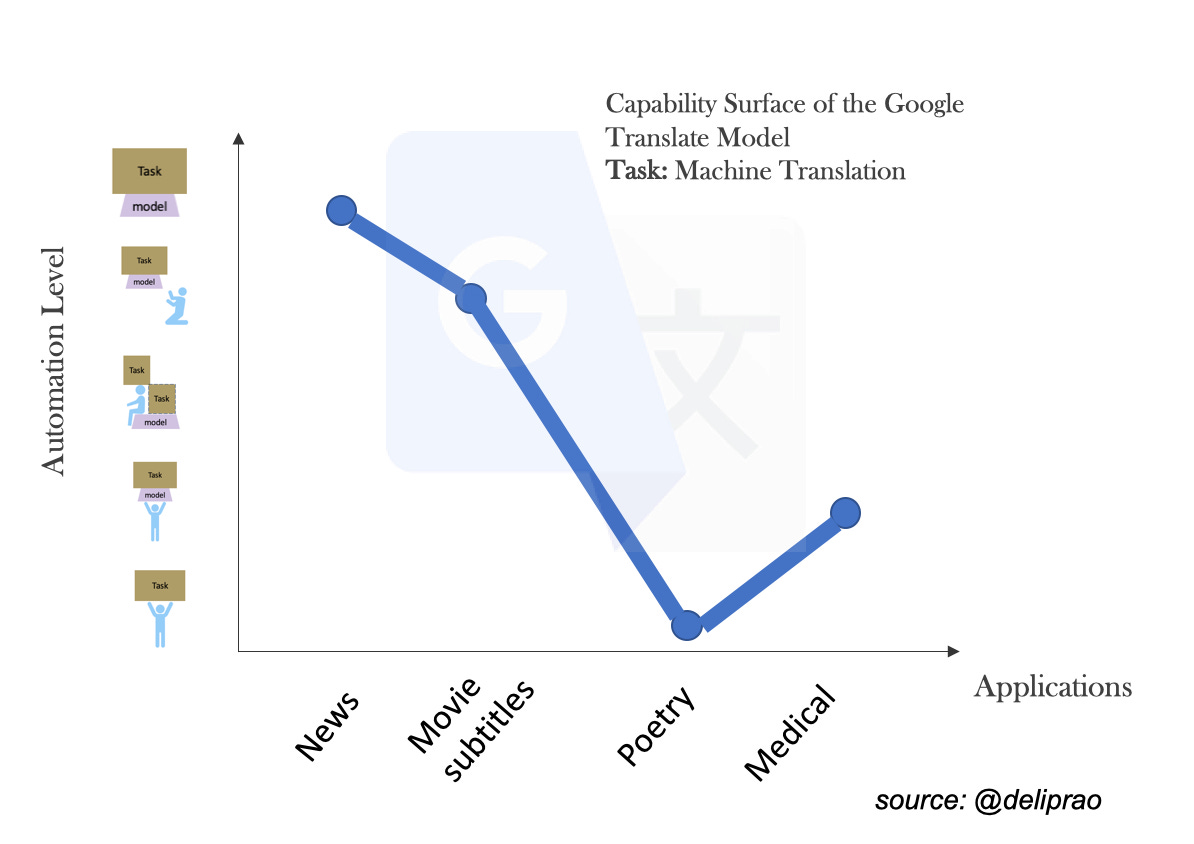
AI Models rarely have a smooth capability surface. We then define Task Entropy as a measure of the roughness of this capability surface. As the model for a task becomes sophisticated, and it is trained with increasingly large datasets and compute, the task entropy, for that fixed model, reduces over time. The task entropy is then a measure of the Automatability of a task using that model.
Aside: All this can be laid out more formally. But for this publication, I am taking a “poetic license” and focusing on developing intuitions.
Capability Surfaces of Few-shot and Zero-shot models
In traditional AI modeling (supervised or fine-tuned), the task is usually fixed, and the application domains can vary. However, in zero-shot and few-shot models, such as GPT-3, not only the application domains vary, but also the tasks can vary too. The tasks solved by a GPT-3 like model may not even be enumerable.
In the case of GPT-3, the task may not even be explicitly defined, except with a list of carefully designed “prompts”. Today, the way to arrive at the “right” prompts is prospecting by querying the model with different prompts until something works. Veteran users now may have developed intuitions for how to structure the prompt for a task-based on experiential knowledge. Despite this care, the predictions may be unreliable, so carefully understanding the risks inherent to the application and engineering around it is indispensable.
Aside: GPT-3 is often touted as a “no code” enabler. This is only partially true. In many real-world problems, such as writing assistance and coding assistance, the amount of boilerplate is so high and the narratives are so predictable in language that it is reasonable to expect GPT-3 to contextually autocomplete big chunks based on the training data it has seen. This is not necessarily a negative. With bigger models like GPT-3 the lego blocks we play with have become incresingly sophisticated, but a significant amount of talent and, many times, coding is needed to put together something non-trivial at scale. As Denny Britz points out (personal communication), “[the cost of error when writing code with GPT-3 is kind of high.] If you need to debug and check GPT’s code, and modify it, are you really saving much from copy/pasting Stackoverflow code?” Another problem with generality of GPT-3 based applications is that they tend to cover only the most common paths, while reality has a fat tail of “one-offs”.
Embracing this way of thinking using capability surfaces and task entropy allows us to develop a gestalt understanding of a model and foresee its many application possibilities without succumbing to hyped up demos and misrepresented text completion examples.
Summary
Automation is not an all or nothing proposition. An AI model’s automation capability is highly conjoined with the task and application it is used in. This realization leads to many exciting partial-automation possibilities that can be highly valuable. Studying a model’s Capability Surface and the Task Entropy can be critical as to applying the model to a task. While capability surfaces of traditional supervised and fine-tuned models are far from being smooth, it only gets worse with few-shot models, where the number of tasks and applications are uncountably many. Studying capability surfaces of complex models is essential for piercing through the hype and ensuring safe deployments of those models.